
EMNLP 2017宾夕法尼亚大学:KnowYourNyms?一种语义关系改编游戏
你和“懂AI”之间,只差了一篇论文
很多读者给芯君后台留言,说看多了相对简单的AI科普和AI方法论,想看点有深度、有厚度、有眼界……以及重口味的专业论文。
为此,在多位AI领域的专家学者的帮助下,我们解读翻译了一组顶会论文。每一篇论文翻译校对完成,芯君和编辑部的老师们都会一起笑到崩溃,当然有的论文我们看得抱头痛哭。
同学们现在看不看得懂没关系,但芯君敢保证,你终有一天会因此爱上一个AI的新世界。
读芯术读者论文交流群,请加小编微信号:zhizhizhuji。等你。
这是读芯术解读的第76篇论文
EMNLP 2017 System Demonstrations
KnowYourNyms?一种语义关系改编游戏
KnowYourNyms?A Game of Semantic Relationships Adaptation
宾夕法尼亚大学
University of Pennsylvania
【摘要】语义关系知识对于自然语言理解至关重要。我们介绍KnowYourNyms,一种用于学习语义关系的web网络游戏。在为用户提供有吸引力体验的同时,应用程序可以收集大量可用于改进语义关系分类器的数据。数据还很有广度地告诉我们人们如何察觉词之间的关系,为心理学和语言学研究提供有用的见解。

1 引言
语义关系的知识可以帮助众多需要从文本推断意义的NLP任务,例如文本分类、内容分析和查询回答。我们将“有目的的游戏”的方法(von Ahn and Dabbish,2004)应用于发现词之间语义关系的任务。我们的目标是通过这种类型的众包来收集大量准确标注的词汇关系。与完全自动或手动关系识别过程相比,由于可以免费获取大量高质量的数据,游戏机制提供了几个优点。
我们创造了一个名为KnowYourNyms的简单游戏。口号是保持你的大脑警觉。它要求玩家在短时间内列出提示的单词。随着秒数的下降,他们可以输入尽可能多的答案,如“什么是海鲜?”或“火山有哪些部分”或“与脂肪相对的是什么”的提示。表1显示了我们的玩家为回应这些问题提供的下义词,别名和反义词。他们的答案对于自然语言理解应用的训练数据很有用,并且可能为心理语言学研究提供有用的视角。
可以去www.know-your-nyms.com去玩KnowYourNyms 。
海鲜的下义词:鱼类54,虾53,龙虾38,蟹36,蛤24,鲑鱼17,牡蛎12,扇贝12,贝类10,贻贝(10),鳕鱼(7),金枪鱼(7),罗非鱼(5),鲸鱼(4),鳟鱼(4),章鱼(4),鲨鱼(4),鱿鱼(3),虾(3)(2),鲶鱼(2),旗鱼(2),鳗鱼(2),寿司(2),低音(2),鱿鱼(2),缪斯(2)。
词语建议一次:muss-,珍珠,suslhi,虾,schrimp,海豹,hadsoxk,螃蟹,棕褐色,scampop,scalop,海草,海豚,fi-,seaww-,snapper,s-,pr-,鲈鱼,汤,沙丁鱼,mahi,herrin,mussells,tipica,tun-,lob-,sa-,osyter,crawdad,roe,swai-,cram-,pa-,鱼子酱,看,鲤鱼,oyste-,sw-,musse-。
火山熔岩:熔岩(32),岩石(12),岩浆(10),山(9),火山口(9),烟(7),喷发(7),灰(6),火(6)(4),热(4),口(3),蒸汽(2),危险(2),粉尘(2),火山(2),锥体(2),核心(2),geodes(2)。
说过一次的:地壳,能源,山,热,村,硫磺,山,火山口,喉咙,pummice,天然气,顶部,侧面,窗台,石头,火花,motlen,法律,日本,开幕,土壤,头,地球,金属,op-,悬崖,cond-,cr-,pl-,流量,压力,喷口,粘土,污染,沉淀物,边缘
脂肪的反义词:瘦(15),瘦(13),苗条(5),苗条(4),小(4),微小(3),合身(3),修剪(2),瘦(2)。
说过一次的:delgado,svelt,narrow,bare,attracive,anorexic,teeny,体重不足,bulemic,形状,under-,wispy,健康,light,smal-,little。

表1 由KnowYourNyms?玩家提供的例子关系
2 相关工作
已经开发了几种具有目的的游戏(GWAP),用于收集语言学标注来构建资源并训练系统(Chamberlain et al, 2013)。Lafourcade(2007)和Fort等(2014年)开发了用法语定义语义关系和依赖关系的游戏。Chamberlain等人(2008)创建了短语侦探来注释和验证共同参考。Jurgens和Navigli(2014)最近提出使用视频游戏将WordNet感觉链接到图像并执行词义消歧。 KnowYourNyms收集英文单词之间的高质量语义关系,以增加Word-Net等资源的覆盖面,并为Paraphrase数据库分配一个分类结构(Ganitkevitch et al,2013)。另外,它还为LexNET(Shwartz和Dan,2016)等训练关系检测系统提供了丰富的数据。到目前为止,已经对小型训练数据集进行了训练(BLESS(Baroni and Lenci,2011)),EVA Lution(Santus et al, 2015),ROOT9(Santus等人,2016)和K&H + N(Necsulescu等人,2015))。
3 系统概述
KnowYourNyms模仿的是ESP游戏或Google Image Labeler这样的GWAP,它使用基于人的计算来收集元数据来改进图像识别分类器(von Ahn and Dabbish,2004)。在高层次上,应用很简单。一旦用户创建一个账户,她可以开始一轮游戏。对于每一轮,系统选择一个特定单词(称为“基本单词”),并要求用户在设定的时限内尽可能多地命名该单词的语义关系对。在分配的时间到期后,这些命名对的记录将存储在我们的数据库中,并作为可能的语义关系的数据点。然后,用户可以看到她的评分性能的显示,这主要是基于其他用户给出的相同关系的数量。以这种方式,这个评分可以反映出“家庭挑战赛”(Family Feud),这是一个受欢迎的游戏节目,激励以与同龄人最相似的方式回答问题。评分屏幕还显示了最常见的问题解答,以合适的方式分配。一旦完成,另一轮开始。这些回合是短暂的(5-20秒,取决于关系类型),这使得游戏在短时间内很有趣,容易上手。
4 系统实现
4.1 架构
Web应用程序使用Django框架构建,使用Python进行所有后端和数据库交互,并使用前端的标准Java,HTML和CSS(包括jQuery,d3.js和Bootstrap Java/CSS)。我们使用AWS Elastic Beanstalk,它将我们的Django Web应用程序部署到AWS EC2服务器。该应用程序具有对用户体验至关重要的多个组件,分为三个主要视图。
欢迎屏幕 该屏幕提供有关游戏的目的信息,什么是语义关系,如何玩,还有一些关于我们的团队信息。当用户登录这个屏幕时,会显示一些关于玩家的统计数据,包括已完成的回合数,总得分和每轮的平均得分。显示四个复选框,一个用于每个可播放的语义关系类型(同义词,反义词,下义词,局部关系词)。这些允许用户选择要玩耍的关系。默认是全部选中。
玩游戏 当每一轮开始时,定时器立即开始。为了回答问题提示,用户可以在文本形式中输入尽可能多的语义关系。每个离散答案都被称为输入字。表单在按Tab或输入时动态生成,因为在这一轮中需要许多输入单词。在20秒结束时,轮次立即结束,用户被指向评分页。
得分页 图1显示了一个玩家在一轮之后所看到的。此评分页面显示玩家的两个项目。第一个是在一轮中所有输入单词的表格分解,将每个单词映射到该单词的分数。它还包括总回合得分。第二个是显示该问题的最佳答案的条形图。在这里,用户可以观察到与整个人群相比,他们识别出和没有识别出的关系。
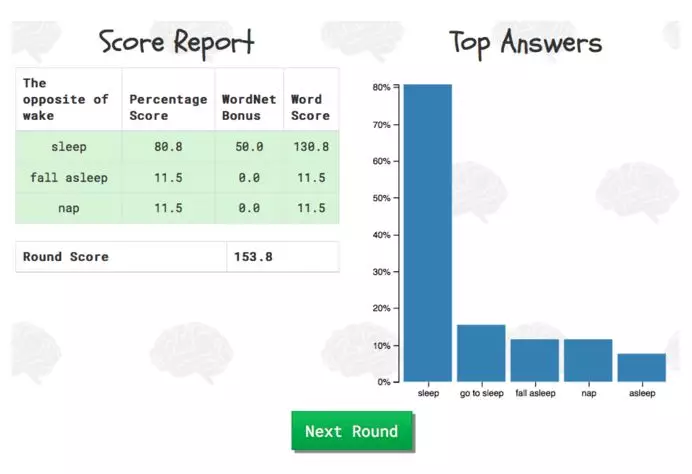
图1 此示例评分页面显示玩家的单词的分数以及最佳答案

图2 KnowYourNyms的程序流程。图的下半部分从用户的角度描绘了应用功能(前端)。该图的上半部分显示了系统后端的组件。请注意,“语义关系分类器”褪色,因为我们在离线设置中对玩家的数据进行了训练和测试(参见第6.2节)。
4.2 基本词选择
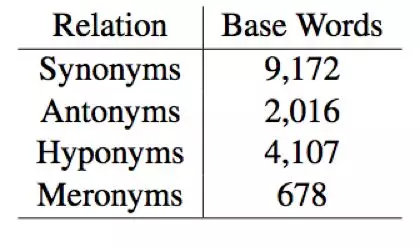
表2 每种关系类型的基本词数量
基础词是每轮问题的基础;它们是潜在的(X,Y)语义关系对中的“X”。良好的基词对于好问题是至关重要的,因为“三角龙triceratops”或一个“球体sphere”的许多部分不一定有很好的同义词。为了解决这些问题,我们为基本单词构建了四个单独的词汇列表,一个用于从WordNet提取的每个允许的语义关系类型。我们选择WordNet中至少有一个同义词或反义词,或至少有三个下位词或别名的词汇。为了确保我们不向用户询问罕见的单词,这样会导致用户停止玩游戏,我们只保留在Google n-gram语料库中出现至少1,000,000次的单字和双字。表2显示了WordNet为每种类型保留的基本单词数。最后,我们集成了一个“跳过”按钮,允许用户跳过他们无法想到任何良好关系的查询的单词。
4.3 得分
我们通过在每轮结束时给予他们一个分数来鼓励玩家。得分是基于给予相同基词和关系类型的其他用户命名的百分比。
最后,该分数也可能通过WordNet奖金来增强,这是一个简单的布尔检查,是否在WordNet中通过此特定关系链接词对。每个单词的总分是这些值的总和,按最终得分表中的降序排序。
4.4 数据可视化
为了使用户能够看到每一轮最通常的反应,评分页中包含一个条形图,显示前5个响应以及给予它们的以前用户的百分比。计分的百分比计算在后端实现。在前端,我们使用数据可视化库d3.js,以便动态创建一个条形图,缩放到适合窗口的大小。这允许在移动设备上看到图形,或者在用户更改桌面窗口的大小时进行动态调整大小。
5 设计决策
5.1 用户识别
我们要求用户创建一个帐户。这一设计决策主要是出于质量控制的考虑。由于我们不期望所有用户能够提供良好答案,因此我们能够清除恶意用户是很重要的,这样使得我们可以收集具有足够高质量的数据用于研究目的。用户识别的另一个好处是它允许不能多次呈现具有相同查询的用户,因为这可能会使数据偏离。
5.2 词汇表选取
每个用户以特定的方式遍历基本单词列表。与完全随机选择相比,这具有不重复单词的优点,直到所有单词用户都玩过。从用户体验的角度来看,几轮过后给用户呈现相同的单词是不能接受的。此外,让不同的用户玩相同的单词是重要的,因为这样可以做到更好的评分和百分比可视化。最后,由于我们以更集中的方式收集较少的基本词汇,所以这种遍历有助于学习高信任关系。为了涵盖更多的单词,我们决定允许少量的随机性,它包括从五个项目的整个词汇列表中随机抽取一个单词。
6 评估
6.1 众包途径
为了评估我们的游戏,我们问了160名在亚马逊土耳其机器人上玩了KnowYourNyms十轮的众包工人。我们的目的是使用数据让游戏成熟,以便普通用户可以根据以前玩家建议的单词来获得分数。虽然这些工人只被要求玩十个回合,但许多人还是打了三十四十甚至一百场比赛。从这些工作人员中,我们收到了超过15,000个用户投入。表3列出了我们迄今收集的关联事项。以下是我们的关系类型中最常用的单词对的例子。同义词包括马马,森林森林,森林树,行走,电力,四面体,看景,频繁,木本林和瘟疫。反义词包括睡眠醒来,有限无限的,前缀后缀,期望不良,相似性差异,相似性不同,搭便车,不成熟,唤醒睡眠和无菌肮脏。名词包括刀柄,刀刀,链条,树林,书封,文字,冰水,月日,水族馆鱼和链条金属。异名词包括海鲜鱼,海鲜虾,海鲜龙虾,睡眠深度,相似性,海鲜蟹,石膏巴黎,亚洲中国人,亚洲日本人和搭车拖车。粗体条目是WordNet中不存在的关系。
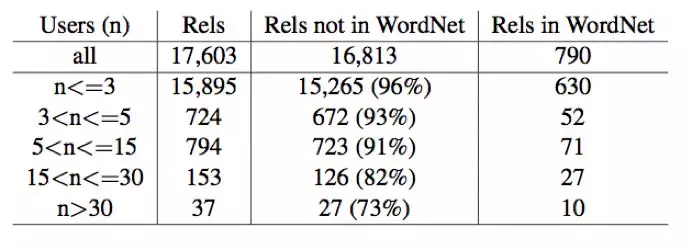
表3 在不同的置信水平下学习的关系的数量,其中置信度是由命名关系的用户(n)的数量来衡量的。我们将这个与WordNet中的相同基数词的关系数量进行比较。
我们调查了群众工作者对游戏的感受,以及他们是否会再玩。前30名人群的玩家是最先完的,他们的分数很多都是空的(游戏依赖于以前的玩家)。那些工作人员的平均得分为3.9 / 5,经验值为3.8 / 5。然而,我们的第二组人群中,已经有了更多的轮次,这样可以提高得分。这些工作人员的平均分数为4.46 / 5,再次玩的打分打出了4.43 / 5。此外,许多第二轮工人留下评论,指出他们“喜欢这个上瘾的游戏”,游戏“很有趣”,“让你快速思考”,“真正唤醒大脑”,并提出有用的建议改进。玩游戏的积极反应(特别是积分变化越来越清晰),证明这个游戏可能会更大规模地运行,并且可以从玩家那里免费收集重要的关键词数据。
6.2 分类器评估
为了演示如何将这个游戏用于收集语义关系分类器的训练数据,我们使用我们的玩家的数据来训练和评估最先进的语义关系分类器LexNET(Shwartz和Dagan,2016)。我们的数据集由至少五个用户提出的8613个名词,反义词,同义词对和6228个随机字对组成。从这14,841对,我们提取了一组951对进行测试,并使用剩余的4675对,其组成词与测试集不与训练和验证重叠。分类器在测试集上实现了总体加权平均F-score为0.34。该实验的全部结果在表4中给出。
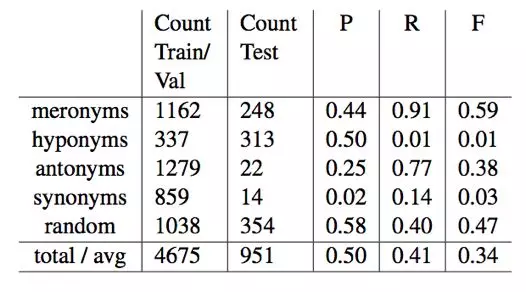
表4 在对KnowYourNyms收集的数据进行训练和评估时,LexNET语义关系分类器的精确度,召回率和F分数。
7 讨论
我使这个游戏有趣的玩法之一是选择容易让人想到的答案的单词和关系类型。尽管我们尝试过滤从WordNet中获取的词汇集合是具有多个WordNet关系的高频词,但我们发现许多玩家被我们的一些问题所困扰。以下是大多数用户按下“通过Pass”按钮的问题示例:
•什么是地质学?(71%通过)
•什么是保护程序?(70%)
•与受孕有什么相反?(67%)
•区别对比是什么?(67%)
•什么是激素?(67%)
•臭名昭着的另一个字是什么?(60%)
•什么是下沉?(56%)
•什么是大麦种类?(56%)
一些提示显然比其他用户更难回答。我们假设抽象词(例如地质学,沉没,溶解)比混淆词更难提供关系。一个单词的注释难度的指标是用户选择跳过的次数:如果他们无法想到任何良好的关系,用户可以选择转到下一轮。我们计算由Brysbaert等人(2014年)建立的数据集中的单词难度之间的相关性被测量为跳过单词的次数与被看到的次数之间的比例以及具体的分数(以下简称“CONCRETE”),其中包含37,058个英文单词和2,896个双字表达式的评分。词从按照低分词(低值)到具有具体意义的词(高值)的5分评分量表上排名。我们希望抽象的单词比较具体的话难以处理,更频繁地被用户跳过。
我们对从KnowYourNyms提取的412个引理关系对执行相关计算。从这些中,40对应于不在CONCRETE中的特定术语和命名实体(例如,染色体,甲基,犹他州,墨西哥,病原学,植物区系,马里兰州)(仅包括85%的注释者已知的词,并排除专有名称)。我们打算使用CONCRETE中的存在作为识别对于注释者来说太难的单词的标准,并且应该被排除在我们的游戏之外。
对于剩余的372个单词的Pearson相关结果表明在词难度和具体性之间为-0.2007的负相关(p <0.001),证实了我们假设更多抽象词更难处理。对于我们的人群中至少10次观察到的CONCRETE 99个引理的修正值更高 0.3851(p <0.001)。
最后,我们打算根据(Vulic等人,2016)中提出的典型和逐步语义类别成员来分析收集的关系,使其对文本承载任务更有用。
8 结论和未来工作
KnowYourNyms?游戏化收集在现有资源中找不到的特定语义关系的单词对的过程。在为用户提供有趣的经验的同时,我们的应用程序可以收集大量可用于改进语义关系分类器和内容分析工具的数据。该应用程序为进一步开发提供了令人兴奋的可能性。随着玩家数量的增长,我们的词汇关系数据集将不断扩大。这将为全面的应用提供新的评估机会,并使我们对于人们如何看待语言关系的理解感到浓厚。
9 软件和数据
我们根据BSD开源许可证发布了我们游戏基础的软件。我们提供如何设置自己的游戏实例的说明,并用您自己的基本词和语义关系类型填充它。该软件可从https://github.com/rossmechanic/know_your_nyms/获得。在我们初次测试游戏时收集的包含语义关系的文件也包含在存储库中。
论文下载链接:
http://www.aclweb.org/anthology/D/D17/D17-2007.pdf

留言 点赞 发个朋友圈
我们一起探讨AI落地的最后一公里
- 2018-10-23新学问在线外教启蒙课携手
- 2018-10-23全力保畅2018年环广西公路自
- 2018-10-23为什么在高铁和飞机场看见
- 2018-10-23这么干 顾客不再问你“新日
- 2018-10-23搭建便捷的空中桥梁 深航顺
- 2018-10-23联想智慧医疗获平安集团数
- 2018-10-23阿里、菜鸟等成立国际物流




- 新学问在线外教启蒙课携手茏翔教育集
- 全力保畅2018年环广西公路自行车世界
- 为什么在高铁和飞机场看见很多孩子都
- 这么干 顾客不再问你“新日电动车怎
- 搭建便捷的空中桥梁 深航顺利开通广
- 联想智慧医疗获平安集团数亿元A轮融
- 阿里、菜鸟等成立国际物流组,包裹
- FEC筷农科技获华旭投资500万天使轮融资
- 顺丰入选未来公司50强,排名第9
- 9月快递企业业绩:头部加速集中,申
网友关注

新学问在线外教启蒙课携手茏翔教
10月19日至21日,“2018·贵州幼教年会”在贵阳国...[详细]

